

Recent nature machine intelligence This study investigated the effectiveness of a voice-based artificial intelligence (AI) classifier in predicting severe acute respiratory syndrome coronavirus-2 (SARS-CoV-2) infection status. SARS-CoV-2 is the microorganism responsible for the coronavirus disease 2019 (COVID-19) pandemic.
 Research: Voice-based AI classifiers show no evidence to screen for COVID-19 better than simple symptom checkers. Image credit: Aliaksandra Post / Shutterstock
Research: Voice-based AI classifiers show no evidence to screen for COVID-19 better than simple symptom checkers. Image credit: Aliaksandra Post / Shutterstock
background
SARS-CoV-2 infection can cause both symptomatic and asymptomatic symptoms, so it is important to develop accurate tests to avoid isolation of the general population. Previous research has shown that AI-based classifiers trained on respiratory audio data can identify SARS-CoV-2 states.
Although these studies have shown the effectiveness of AI-based classifiers, many challenges surfaced when applying them to real-world settings. Factors that held off on applying AI-based classifiers include sampling bias, unverified data on participants' COVID-19 status, and delays between infection and audio recording. It is essential to determine whether audio biomarkers of COVID-19 are specific to SARS-CoV-2 infection or are inappropriate confounding signals.
About research
Current research focuses on determining whether speech-based classifiers can be accurately used for screening for COVID-19 infection. A large-scale polymerase chain reaction (PCR) dataset linked to audio-based his COVID-19 screening (ABCS) was used. Participants from the Real-Time Assessment of Community Transmission (REACT) program and the National Health Service (NHS) Test and Trace (T+T) service were invited to participate in the study. All relevant demographic data were extracted from T+T/REACT records.
Participants were asked to answer survey questions and record four audio clips. For the audio recordings, subjects were asked to make a “ha” sound and exhale three times in a row after reading a particular sentence. Additionally, participants were asked to record one and three consecutive forced coughs. All recordings were documented in .wav format. The quality of the audio recordings was evaluated and 5,157 recordings were removed due to quality-related issues.
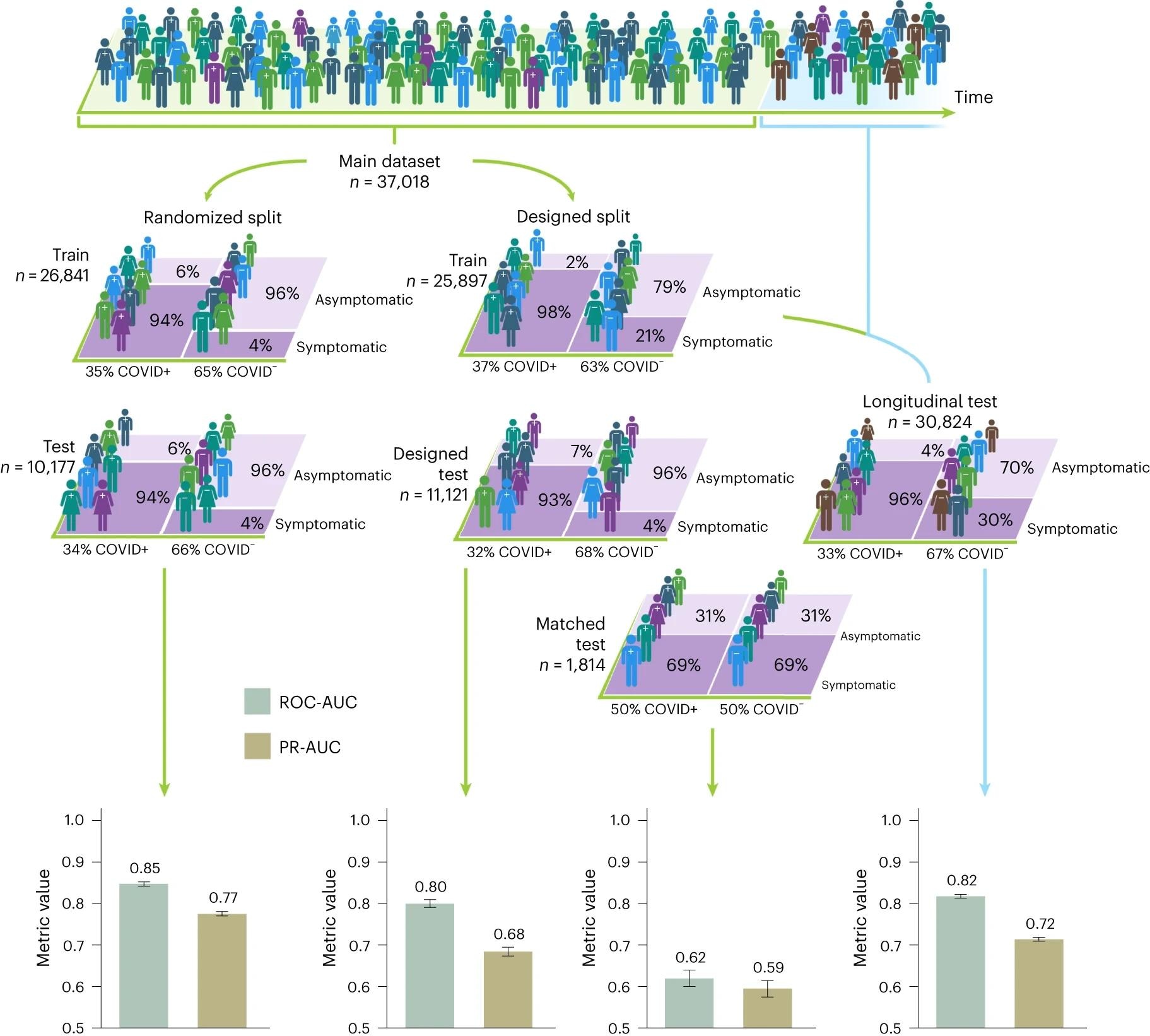 The figures represent study participants and their corresponding COVID-19 status, with different colors representing different demographics and symptom characteristics. When participants were randomly split into training and test sets, the randomized split model performed well in detecting COVID-19, achieving an AUC above 0.8. However, the performance on the matched test set is seen to drop to an estimated AUC of 0.60 to 0.65, where AUC 0.5 represents random classification. Inflation in classification performance is also observed in test sets designed outside the distribution. For example, there is no overlap in design test sets, where the set of selected demographic groups appears only in the test set, and in longitudinal test sets. Transmission time between training and testing instances. The 95% confidence intervals calculated by the normal approximation method are displayed along with the corresponding n numbers for the training and test sets.
The figures represent study participants and their corresponding COVID-19 status, with different colors representing different demographics and symptom characteristics. When participants were randomly split into training and test sets, the randomized split model performed well in detecting COVID-19, achieving an AUC above 0.8. However, the performance on the matched test set is seen to drop to an estimated AUC of 0.60 to 0.65, where AUC 0.5 represents random classification. Inflation in classification performance is also observed in test sets designed outside the distribution. For example, there is no overlap in design test sets, where the set of selected demographic groups appears only in the test set, and in longitudinal test sets. Transmission time between training and testing instances. The 95% confidence intervals calculated by the normal approximation method are displayed along with the corresponding n numbers for the training and test sets.
research result
In this study, a respiratory acoustic dataset of 67,842 people was collected. Of these, 23,514 people tested positive for the new coronavirus. All data were linked to PCR test results. It should be noted that compared to the T+T channel, the most significant number of her COVID-19 negative participants were collected from her six REACT rounds.
The dataset considered in this study showed a promising dataset covering the whole of England. No significant association was found between geographic location and COVID-19 status. The country with the highest Covid-19 imbalance was Cornwall. Previous studies have shown recruitment bias in ABCS, particularly related to age, language, and gender, in both training data and test sets. Despite this bias, the training dataset was balanced according to age and gender across the COVID-19 positive and COVID-19 negative subgroups.
Consistent with previous studies, the unadjusted analysis conducted in this study showed that the AI classifier was able to predict COVID-19 status with high accuracy. However, we observed poor performance of the AI classifier in detecting SARS-CoV-2 status when measured confounders were matched.
Based on this finding, the current study proposed some guidelines to correct the effects of recruitment bias for future research. Some of the recommendations are listed below.
- Audio samples stored in the repository must include details of research recruitment criteria. Additionally, relevant information about the individual such as gender, age, time of COVID-19 test, SARS-CoV-2 symptoms, and location must be documented along with the audio recording.
- To control recruitment bias, all confounding factors must be identified and matched.
- Experimental designs should be created with possible biases in mind. In most cases, data matching reduces sample size. Observational studies recruit participants with a focus on maximizing the likelihood of matching the measured confounders.
- The predicted values of the classifier should be compared with the results of standard protocols.
- You need to evaluate the predictive accuracy of your AI classifier. However, predictive accuracy, sensitivity, and specificity vary depending on the target population.
- The usefulness of a classifier must be evaluated for each test result.
- Replication studies should be conducted in randomized cohorts. Additionally, pilot studies should be conducted in real-world settings based on domain-specific utility.
conclusion
The current study has limitations, including the possibility of potential unmeasured confounders across REACT and T+T recruitment channels. For example, PCR tests for COVID-19 were administered several days after self-testing for symptoms. In contrast, PCR tests in REACT were performed on predetermined days, regardless of the onset of symptoms. Although most of the confounders were matched, residual predictive variation may exist.
Despite the limitations, this study highlighted the need to develop accurate machine learning evaluation procedures to obtain unbiased output. Furthermore, it has become clear that detecting and controlling confounding factors across many AI applications is difficult.
Reference magazines:
- Coppock, H. et al. (2024) Voice-based AI classifiers show no evidence of improved screening for COVID-19 over simple symptom checkers. nature machine intelligence. 1-14. DOI: 10.1038/s42256-023-00773-8, https://www.nature.com/articles/s42256-023-00773-8